# Day03 函数与指针
# 本节关键词
函数签名闭包=函数+引用环境defer生效范围所在函数defer+recover捕获所在函数,即使无异常 e := recover() -> nil变量的值,有自己类型;变量的值,有对应地址,且对应地址也有自己的类型,如*int、*string、*bool申请内存 make 与 new
# 函数的定义
func bar(x int, y string)(string, bool){
}
# 函数的参数
- 参数的类型简写
func bar(x, y int) - 不定长参数
func bar(x ...int) - 没有默认参数
# 函数返回值
- 多个返回值 func calc(x, y int) (int, int)
- 命名返回值 func calc(x, y int) (sum, sub int)
- 如当返回值类型为slice,可以返回nil,当作有效的slice类型
# 函数进阶
# 变量的作用域
- 全局变量 没有global直接,函数内部可直接修改
- 局部变量
- 函数内定义的变量
- 语句块定义的变量
if v, ok := m["linda"]; ok{ fmt.Println(v) }
只要以type关键字开头的都是定义类型。
type calculation func(int, int) int
func add(x, y int) int {
return x + y
}
func sub(a, b int) int {
return a - b
}
func f15() {
var x calculation
fmt.Printf("%T\n", x) // main.calculation
fmt.Println(x == nil) // true
x = add // 把add赋值给x
res := x(10, 20) // ???
fmt.Println(res)
add(10, 20)
}
# 函数签名
- 函数签名一样 --> 函数输入与返回值的参数类型、个数以及顺序要一致
- 函数签名 --> 与函数名、输入参数名以及返回值参数名无关
func fi(name string, age int) {}
func fj(age int, name string) {}
type MyFF func(string, int)
func f16() {
var mf MyFF
mf = fi
// mf = fj // 函数签名不一致
mf("ddd", 1)
}
# 高阶函数
高阶函数分为函数作为参数和函数作为返回值两部分
// 函数作为参数
func f17(x, y int, op calculation) int {
res := op(x, y)
return res
}
// 命名返回值
// 1.函数内部声明了一个变量res
// 2.返回值是res
func f18(x, y int, s string) (res func(int, int) int) {
switch s {
case "+":
return add
case "-":
return sub
}
return // 默认就把res返回
}
func f19(x, y int, s string) func(int, int) int {
var res func(int, int) int // res = nil
switch s {
case "+":
return add
case "-":
return sub
}
return res
}
# 匿名函数
// 把匿名函数赋值给变量
func f33() func() {
f1 := func() {
fmt.Println("美好的周末就要结束啦~")
}
// var f2 func() = func() {
// fmt.Println("美好的周末就要结束啦~")
// }
return f1
}
// 匿名函数立即执行
func f34() {
func() {
fmt.Println("美好的周末就要结束啦~")
}()
}
# 闭包
闭包指的是一个函数和与其相关的引用环境组合而成的实体,简单来说,闭包=函数+引用环境
// 闭包
func adder() func() int {
var x int
// 函数内部使用了它外部函数的变量x
f := func() int {
x++
return x
}
// 把匿名函数当成返回值返回了
return f
}
func adder2() func(int) int {
var x int
f := func(y int) int {
x += y // x = x+y
return x
}
return f
}
// 定义一个累加器
// x的值会被返回的函数一直占用着
func adder3(x int) func(int) int {
f := func(y int) int {
x += y // x = x+y
return x
}
return f
}
func makeSuffixFunc(suffix string) func(string) string {
return func(name string) string {
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
}
- 如 f = adder() 得到闭包f其中x一直跟随者f的生命周期,可以联系Python实例化一个对象,对象是有状态
# defer
Go语言中的defer语句会将其后面跟随的语句进行延迟处理,在defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行
func main() {
fmt.Println("start")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("end")
}
// 先输出 start end,再输出 3 2 1
- 什么场景会用到defer
- 释放资源
- 关闭文件
- 释放连接
- defer的执行顺序
- 先注册的后执行
- defer的执行时机
- 返回值赋值之后,底层RET指令之前
- defer语句不能接收返回值
defer x := sub(10, 2) - defer执行时机
return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步
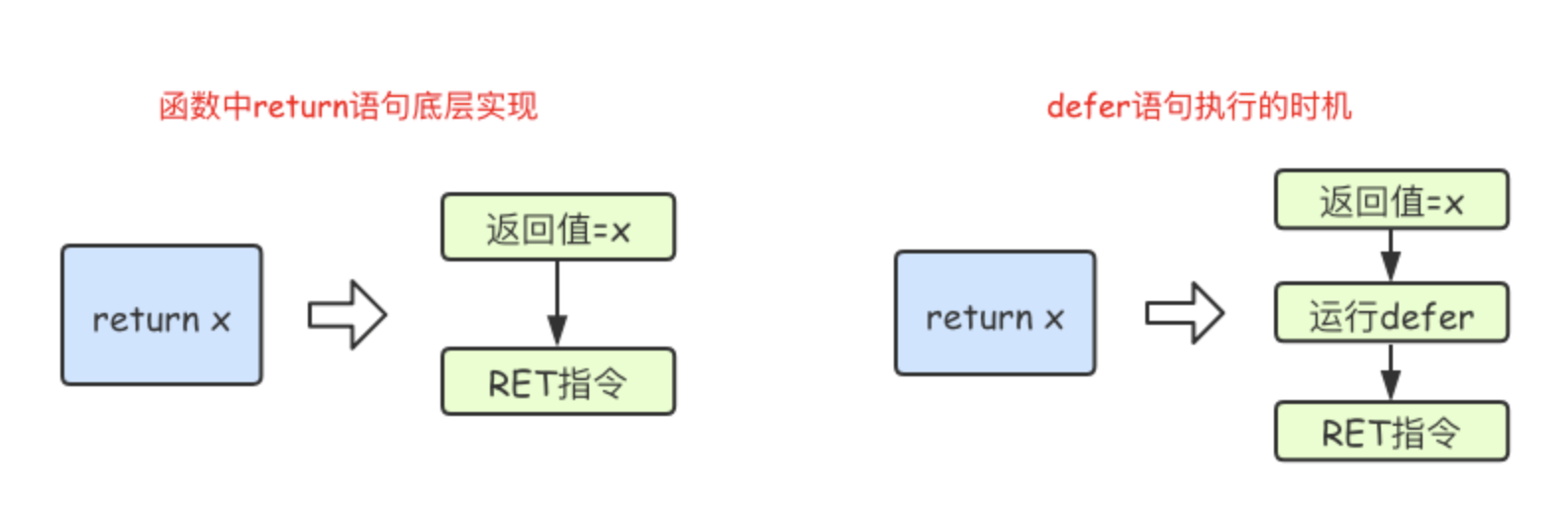
func f2() (x int) {
defer func() {
x++
}()
return 5
}
// 第一步给返回值赋值,返回值定义了变量 x,所以 x = 5
// 第二步执行 defer语句 func(){x++}() 是一个闭包会影响x的值,所以 x++ --> x = x + 1
// 第三步RET指令 x = 6 返回
- 注意:
defer注册要延迟执行的函数时该函数所有的参数都需要确定其值
# 内置函数

# panic与recover
func funcA() {
fmt.Println("func A")
}
func funcB() {
defer func() {
err := recover()
//如果程序出出现了panic错误,可以通过recover恢复过来
if err != nil {
fmt.Println("recover in B")
}
}()
panic("panic in B")
}
func funcC() {
fmt.Println("func C")
}
func main() {
funcA()
funcB()
funcC()
}
- recover()必须搭配defer使用
- defer一定要在可能引发panic的语句之前定义
# 指针
ptr := &v // v的类型为T
- v:代表被取地址的变量,类型为T
- ptr:用于接收地址的变量,ptr的类型就为
*T,称做T的指针类型,*代表指针
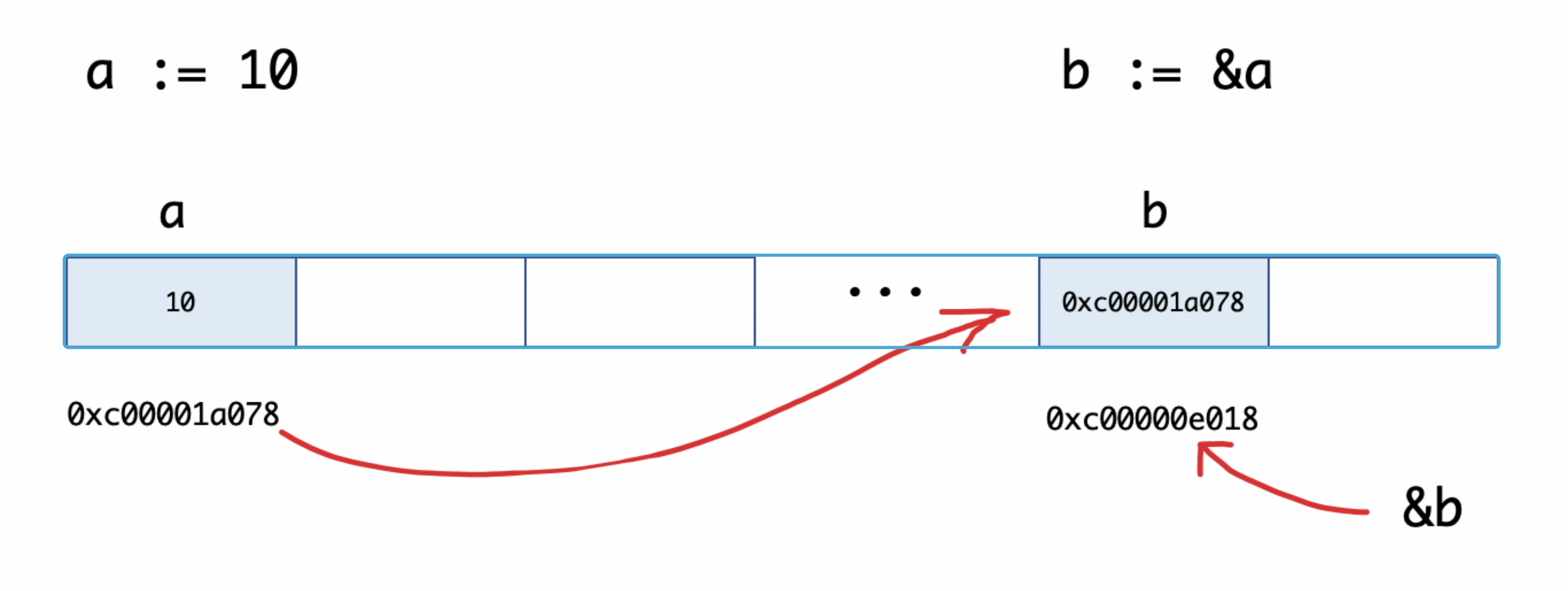
func main() {
a := 10
b := &a // 取变量a的地址,将指针保存到b中
fmt.Printf("a:%d ptr:%p\n", a, &a) // a:10 ptr:0xc00001a078
fmt.Printf("b:%p type:%T\n", b, b) // b:0xc00001a078 type:*int
fmt.Println(&b) // 0xc00000e018
c := *b // 指针取值(根据指针去内存取值)
fmt.Printf("type of c:%T\n", c)
fmt.Printf("value of c:%v\n", c)
}
就两个操作:
- 取变量x的内存地址:
&x得到的是指针 - 有了指针变量p,
*p根据内存地址去找值
总结:取地址操作符&和取值操作符*是一对互补操作符,&取出地址,*根据地址取出地址指向的值
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
- 对变量进行取地址
&操作,可以获得这个变量的指针变量 - 指针变量的值是指针地址
- 对指针变量进行取值
*操作,可以获得指针变量指向的原变量的值
// 指针传值示例
func modify1(x int) {
x = 100
}
func modify2(x *int) {
*x = 100
}
func main() {
a := 10
modify1(a)
fmt.Println(a) // 10
modify2(&a)
fmt.Println(a) // 100
}
# 内置函数 new与make
// 引发 panic
func main() {
var a *int
*a = 100
fmt.Println(*a)
var b map[string]int
b["分数"] = 100
fmt.Println(b)
}
- Go语言中对于引用类型的变量,在使用的时候不仅要声明它,还要为它分配内存空间,否则我们的值就没办法存储
# 内置函数 new
// 源码 a := new(int)
func new(Type) *Type
- new函数不太常用,使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值
func main() {
a := new(int)
b := new(bool)
fmt.Printf("%T\n", a) // *int
fmt.Printf("%T\n", b) // *bool
fmt.Println(*a) // 0
fmt.Println(*b) // false
}
# 内置函数 make
// make 源码
func make(t Type, size ...IntegerType) Type
make也是用于内存分配的,区别于new,它只用于slice、map以及channel的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针
# new与make小结
- 二者都是用来做内存分配的;
- make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
- 而new用于值类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针
# 课后作业
package main
/*
你有50枚金币,需要分配给以下几个人:Matthew,Sarah,Augustus,Heidi,Emilie,Peter,Giana,Adriano,Aaron,Elizabeth。
分配规则如下:
a. 名字中每包含1个'e'或'E'分1枚金币
b. 名字中每包含1个'i'或'I'分2枚金币
c. 名字中每包含1个'o'或'O'分3枚金币
d: 名字中每包含1个'u'或'U'分4枚金币
写一个程序,计算每个用户分到多少金币,以及最后剩余多少金币?
程序结构如下,请实现 ‘dispatchCoin’ 函数
*/
var (
coins = 50
users = []string{
"Matthew", "Sarah", "Augustus", "Heidi", "Emilie", "Peter", "Giana", "Adriano", "Aaron", "Elizabeth",
}
distribution = make(map[string]int, len(users))
)
func main() {
left := dispatchCoin()
fmt.Println("剩下:", left)
}
// dispatchCoin 按规则分金币,返回剩余的金币数
func dispatchCoin()int{
// 1.依次给每个人(拿到每个人的名字)
for _, name := range users{
userNum := dispatchForUser(name)
// 3.登记每个人分了多少金币
distribution[name] = userNum
// 4.计算剩下的金币数
coins = coins - userNum
}
return coins
}
func dispatchForUser(name string)int{
// 2.按规则分金币(对名字判断规则)
// 2.1 记录下每个人分的金币数
userNum := 0
for _, c := range name{ // Matthew
switch c{
case 'e', 'E':
userNum = userNum + 1
case 'i', 'I':
userNum = userNum + 2
case 'o', 'O':
userNum = userNum + 3
case 'u', 'U':
userNum = userNum + 4
}
}
return userNum
}名字中每包含1个'e'或'E'分1枚金币