# Day06 BTREE 索引
# 本节关键词
聚簇索引辅助索引
表可以看做一本书,索引就是书的目录
- 优化查询
- 索引影响着加锁的过程
# 索引概述
- 种类概述
BTREE : 99.9% ---> InnoDB
RTREE : no ---> MongoDB
HASH : MEM引擎 --> Redis
FULLTEXT : TEXT类型 --> ES
- BTREE 适合于做范围查询
B-TREE : 普通的BTREE
B+TREE : 叶子节点双向指针
B++TREE : 枝节点双向指针
# MySQL BTREE 索引
- B+TREE 数据结构
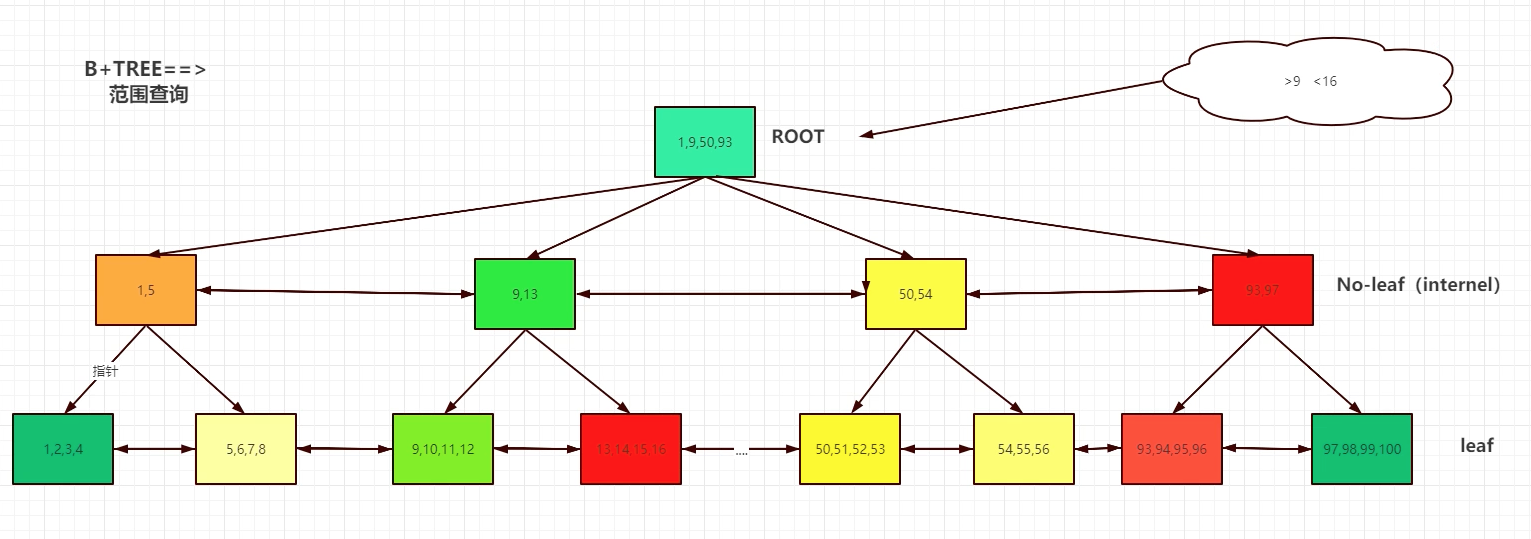
MySQL BTREE 索引 两类结构
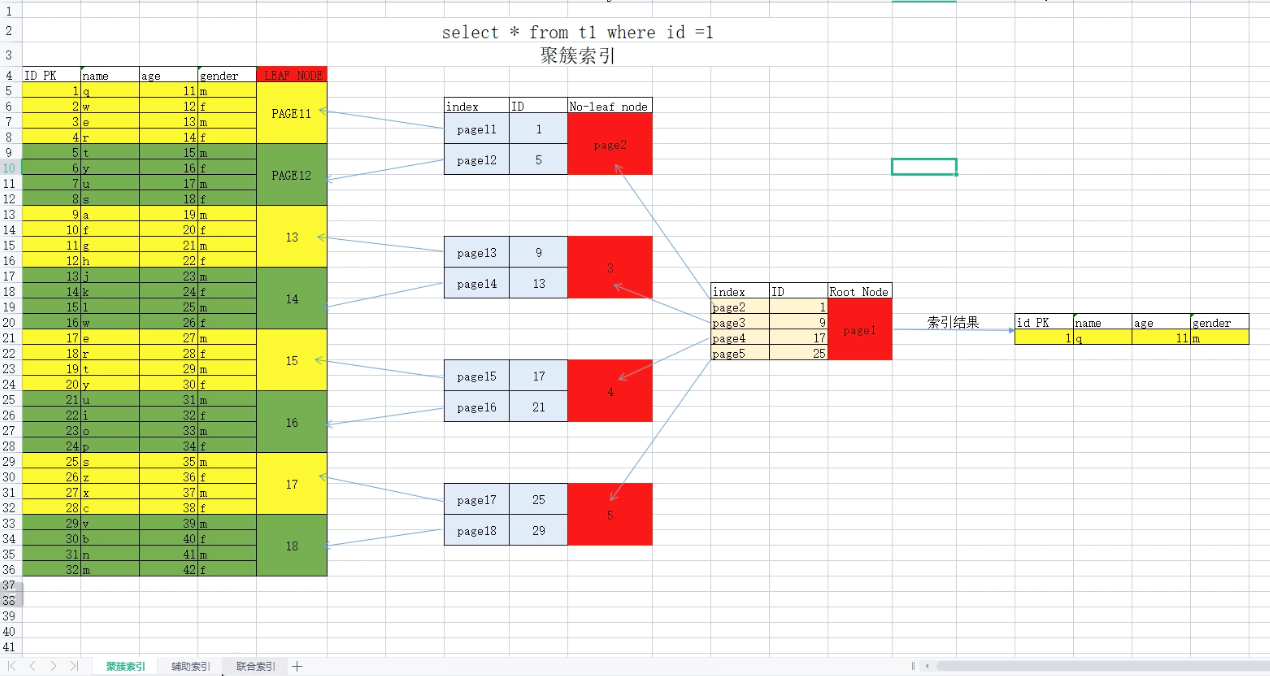
- Clustered Indexes 聚簇索引
- Secondary Indexes 辅助索引
# Clustered Indexes 聚簇索引
# Clustered Indexes 聚簇索引
原理概念
- 聚簇(extent区):默认连续的64个数据页(page, 16K),大小默认1M。区是聚簇索引分配叶子节点空间的最小单元
- IOT组织表:聚簇索引组织表,表的数据行都是(逻辑)有序的存储到聚簇索引中,按照聚簇索引组织存储(叶子节点)
创建聚簇索引
1. 如果表中设置了主键(例如ID列),自动根据ID列生成聚簇索引
2. 如果没有设置主键,自动选择第一个唯一键的列作为聚簇索引
3. 自动生成隐藏(6字节row_id)的聚簇索引
聚簇索引组织表:将逻辑上连续的数据,在磁盘存储时也是物理(同一个区内)上连续的
1. 录入数据时,按照聚簇索引组织存储数据,在磁盘上有序存储数据行
2. 加速查询,基于ID作为条件的判断查询
BTREE构建过程:
a. 叶子节点: 存储数据行时就是有序的,直接将数据行的page作为叶子节点(相邻的叶子结点,有双向指针)
b. 枝节点 : 提取叶子节点ID的范围+指针,构建枝节点(相邻枝节点,有双向指针)
c. 根节点 : 提取枝节点的ID的范围+指针,构建根节点
# in 属于范围参数,可选择 union all
mysql> desc select * from city where id in (10, 100, 3000);
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | city | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 3 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
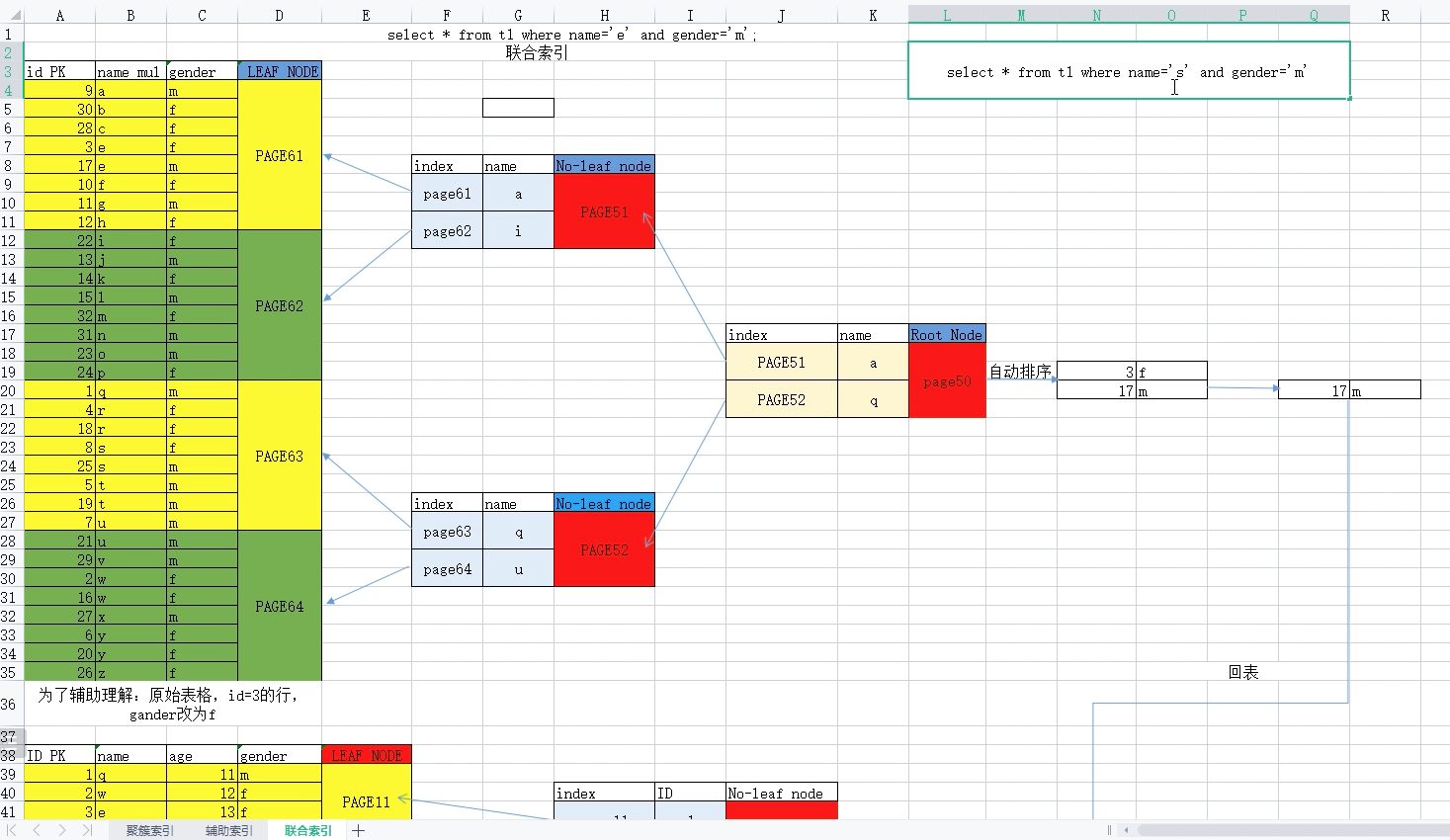
# Secondary Indexes 辅助索引
# Secondary Indexes : 辅助索引
普通单列索引 alter table t1 add index idx_name(name);
普通多列索引 alter table t1 add index idx_name(name, code);
1. where 要包含最左前缀索引字段
2. 建多列索引时 重复值最少的字段放到最左侧
普通唯一索引
前缀索引 大值字段,取前固定长度建立索引
- 单列索引

- 多列索引
问答:回表是什么? 回表会带来什么问题? 怎么减少回表?
a. 按照辅助索引列,作为查询条件时,先查找辅助索引树得到ID,再到聚簇索引树查找数据行的过程。
b. IO量多、IO次数多、随机IO会增多、SQL层和Engine交互多次,会导致IO偏高、CPU偏高
c. 减少回表建议:
1. 辅助索引能够完全覆盖查询结果,可以使用联合索引
2. 尽量让查询条件精细化,尽量使用值多的列作为查询条件,如手机号、身份证号等
3. 优化器:MRR(Multi-Range-Read)、ICP(index condition pushdown)锦上添花的功能
mysql> select @@optimizer_switch;
mysql> set global optimizer_switch='mrr=on';
功能:
1. 辅助索引查找后得到ID值,进行自动排序
2. 一次性回表,很有可能受到B+TREE中的双向指针的优化查找
问答:索引树高度的影响因素? 如何解决?
a. 高度越低越好
b. 数据行越多,高度越高
1. 分区表 一个实例里管理
2. 按照数据特点,进行归档表 pt-archiver 冷热数据分离
3. 分布式中间件架构 针对海量数据、高并发业务主流方案
4. 分布式数据库,如TiDB
5. 在设计方面,满足三大范式,如大字段业务拆分
c. 主键规划:长度过长
1. 主键,尽量使用自增数字列
d. 列值长度越长,数据量大的话,会影响到高度
1. 使用前缀索引 100字符 只取前10个字符,构建索引树
e. 数据类型的选择
选择合适的、简短的数据类性
例如:
1. 存储人的年龄 ,使用 tinyint 和 char(3)哪个好一些
2. 存储人名,char(20)和varchar(20)的选择哪一个好
a. 站在数据插入性能角度思考,应该选:char
b. 从节省空间角度思考,应该选:varchar
c. 从索引树高度的角度思考,应该选:varchar
建议使用varchar类型存储变长列值
# 库表创建索引
- 索引压测
mysql> source /root/t100w.sql -- 网上可搜到该sql语句文件
-- 建索引之前测一次,索引之后再测一次对比
[root@ni-ning ~]# mysqlslap --defaults-file=/etc/my.cnf --concurrency=2 --iterations=1 --create-schema='test' --query="select * from test.t100w where k1='aa'" engine=innodb --number-of-queries=10 -uroot -p123 -verbose;
--concurrency=100 : 模拟同时100会话连接
--create-schema='test' : 操作的库是谁
--query="select * from test.t100w where k2='780P'" :做了什么操作
--number-of-queries=2000 : 一共做了多少次查询
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 5.978 seconds
Minimum number of seconds to run all queries: 5.978 seconds
Maximum number of seconds to run all queries: 5.978 seconds
Number of clients running queries: 2
Average number of queries per client: 5
- 创建应用删除索引
# 查询索引
desc test.t100w;
Key
PK --> 主键(聚簇索引)
MUL --> 辅助索引
UNI --> 唯一索引
show index from test.t100w;
# 新增单列辅助索引
alter table test.t100w add index idx_k2(k2);
select * from test.t100w where k2='780P';
# 删除索引
alter table test.t100w drop index idx_k2;
# 新增联合辅助索引
alter table test.t100w add index idx_k2_k1(k2, k1);
# 新增前缀辅助索引
alter table test.t100w add index idx_k2_2(k2(2));