# Day09 CR事务与锁
# LSN介绍
- LSN
- LSN主要用于发生crash时对数据进行recovery,LSN是一个一直递增的整型数字,表示事务写入到日志的字节总量
- LSN号串联起一个事务开始到恢复的过程
show engine innodb status;
---
LOG
---
Log sequence number 101484376 -- 当前系统最大的LSN号
Log flushed up to 101484376 -- 当前已经写入redo日志文件的LSN
Pages flushed up to 101484376 -- 已经将更改写入脏页的lsn号
Last checkpoint at 101484376 -- 系统最后一次刷新buffer pool 脏页数据到磁盘的checkpoint
所以:每个数据页有LSN,重做日志有LSN,checkpoint有LSN
# CKPT介绍
- sharp checkpoint 正常关闭时,触发所有脏页都写入到磁盘
- fuzzy checkpoint
1. master thread checkpoint
差不多以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘,这个过程是异步的,不会阻塞用户查询
mysql> show variables like '%io_cap%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_io_capacity | 200 |
| innodb_io_capacity_max | 2000 |
+------------------------+-------+
PCI-E 2000-3000 4000-6000
flash 5000-8000 10000-16000
2. flush_lru_list checkpoint
mysql> show variables like '%lru%depth%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_lru_scan_depth | 1024 |
+-----------------------+-------+
参数innodb_lru_scan_depth控制lru列表中可用页的数量,默认是1024
3. async/sync flush checkpoint
log file快满了,会批量的触发数据页回写,这个事件触发的时候又分为异步和同步,不可被覆盖的
redo log占log file的比值:75%--->异步、90%--->同步
4. dirty page too much checkpoint
脏页太多检查点,为了保证buffer pool的空间可用性的一个检查点
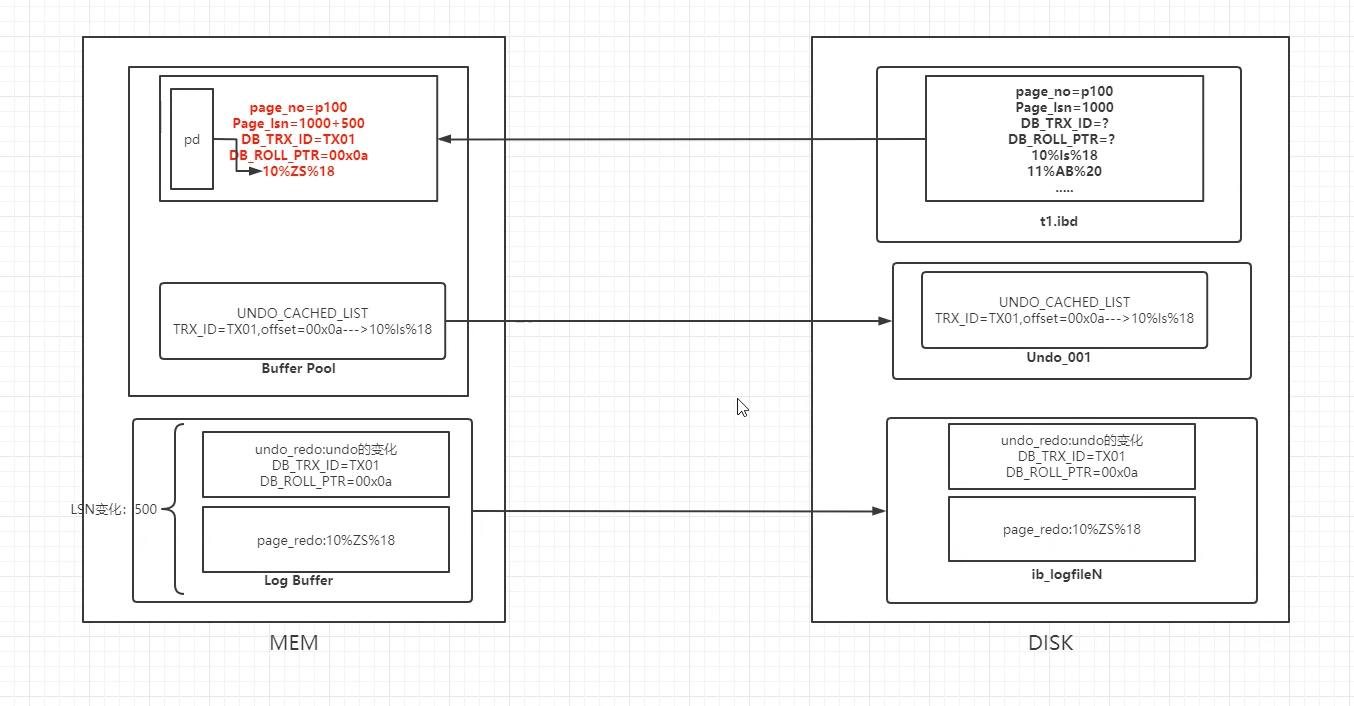
# CR(Crash Recovery)
- 选择InnoDB,崩溃后可恢复,安全性高
# 事务介绍
- 事务控制语句
# 开启事务
begin;
# 提交事务
commit;
# 回滚事务
rollback;
注意:事务生命周期中,只能使用DML语句(select、update、delete、insert)
- 提交与回滚
1. 重新开启 begin 隐式提交
begin
a语句
begin
2. 非事务语句导致提交
DDL语句:(ALTER、CREATE和DROP)
DCL语句:(GRANT、REVOKE和SET PASSWORD)
锁定语句:(LOCK TABLES 和 UNLOCK TABLES)
还有其他
TRUNCATE TABEL
LOAD DATA INFILE
SELECT FOR UPDATE
3. 隐式回滚
- 会话窗口被关闭
- 数据库关闭
- 出现事务冲突(死锁)
# 事务的ACID
A 原子性
一个事务生命周期中的DML语句,要么全成功要么全失败,不可以出现中间状态
通过:Undo来保证
C 一致性
事务发生前、中、后,数据最终保持一致
通过:CR + DWB
I 隔离性
事务操作数据行的时候,不会受其他事务的影响
读写隔离:隔离级别、MVCC
写写隔离:锁、隔离级别
D 持久性
事务一旦提交,永久生效(落盘)
通过:Redo CKPT
# 事务隔离级别
作用:实现事务工作期间的"读"隔离
读?--> 数据页(记录)的读
mysql> select @@global.transaction_isolation;
+--------------------------------+
| @@global.transaction_isolation |
+--------------------------------+
| REPEATABLE-READ |
+--------------------------------+
# RU : READ-UNCOMMITTED 读未提交
可以读取到事务未提交的数据。隔离性差,会出现脏读(当前内存读)、不可重复读、幻读问题(更新数据时,其他事务插入新记录)
# RC : READ-COMMITTED 读已提交(可以用)
可以读取到事务已提交的数据。隔离性一般,不会出现脏读问题,但是会出现不可重复读,幻读问题
# RR : REPEATABLE-READ 可重复读(默认)
防止脏读(当前内存读)、不可重复读,幻读问题。需要配合锁机制来避免幻读
# SE : SERIALIZABLE 可串行化
结论: 隔离性越高,事务的并发读就越差
set global transaction_isolation='READ-UNCOMMITTED';
set global transaction_isolation='READ-COMMITTED';
set global transaction_isolation='REPEATABLE-READ';
# 锁概述
全局锁
global
db
table
Engine
record
gap
next lock
示例 备份阶段 全局锁 大查询
总结:
1. 不要业务繁忙时实现 Online DDL操作,或者备份操作,容易触发全局锁
2. 掌握锁的排查技巧
- 锁的排查
select * from performance_schema.metadata_locks;
select * from performance_schema.threads where thread_id = 55;
-- kill进程号定位
show processlist;
kill 11;
-- 详细SQL定位
select * from performance_schema.events_statements_current where thread_id = 55;
select * from performance_schema.events_statements_history where thread_id = 55;
-- 锁定超时时间设置
mysql> show variables like 'lock_wait_timeout';
+-------------------+----------+
| Variable_name | Value |
+-------------------+----------+
| lock_wait_timeout | 31536000 |
+-------------------+----------+